library(nabla)
#>
#> Attaching package: 'nabla'
#> The following objects are masked from 'package:stats':
#>
#> D, derivMotivation
The D operator composes to arbitrary order:
D(f, x, order = k) returns the
-th
derivative tensor. Gradients
()
and Hessians
()
are standard tools for maximum likelihood estimation. But third-order
derivatives unlock additional diagnostic information — in particular,
the asymptotic skewness of the MLE.
This vignette demonstrates D(f, x, order = 3) on a Gamma
MLE problem, computing:
- The score and observed information (first and second derivatives)
- The third-order derivative tensor (a array)
- The asymptotic skewness of the MLE
- Monte Carlo validation of the theoretical skewness
The Gamma model
We observe with shape and rate . The log-likelihood, written in terms of sufficient statistics and , is:
This model is ideal for demonstrating third-order AD because:
- It involves
lgamma, exercisingnabla’s special function support - The Hessian depends only on , not the data (observed information = expected information)
- Third derivatives involve
psigamma(alpha, deriv = 2)(tetragamma)
# Simulate data
set.seed(42)
n <- 200
alpha_true <- 3
beta_true <- 2
x_data <- rgamma(n, shape = alpha_true, rate = beta_true)
# Sufficient statistics
S1 <- sum(log(x_data))
S2 <- sum(x_data)
# Log-likelihood using sufficient statistics
ll_gamma <- function(theta) {
alpha <- theta[1]; beta <- theta[2]
n * alpha * log(beta) - n * lgamma(alpha) +
(alpha - 1) * S1 - beta * S2
}Score and observed information
At the MLE, the score (gradient of the log-likelihood) should be approximately zero. The observed information matrix is the negative Hessian.
# Score at MLE — should be near zero
score <- gradient(ll_gamma, theta_hat)
score
#> [1] -5.669643e-05 1.179905e-04
# Observed information
H <- hessian(ll_gamma, theta_hat)
J <- -H
cat("Observed information matrix:\n")
#> Observed information matrix:
J
#> [,1] [,2]
#> [1,] 84.34221 -100.8634
#> [2,] -100.86337 144.3182Verify against analytical formulas. For the Gamma model:
- where is trigamma
alpha_hat <- theta_hat[1]; beta_hat <- theta_hat[2]
J_analytical <- matrix(c(
n * trigamma(alpha_hat), -n / beta_hat,
-n / beta_hat, n * alpha_hat / beta_hat^2
), nrow = 2, byrow = TRUE)
cat("Max |AD - analytical| in J:", max(abs(J - J_analytical)), "\n")
#> Max |AD - analytical| in J: 0Standard errors from the inverse information:
Third-order derivative tensor
The real payoff of D(f, x, order = 3) is the third-order
derivative tensor
.
For a two-parameter model, this is a
array with 8 entries (though symmetry reduces the distinct values).
T3 <- D(ll_gamma, theta_hat, order = 3)
T3
#> , , 1
#>
#> [,1] [,2]
#> [1,] 35.08977 0.00000
#> [2,] 0.00000 -50.86709
#>
#> , , 2
#>
#> [,1] [,2]
#> [1,] 0.00000 -50.86709
#> [2,] -50.86709 145.56419Verify each entry analytically. For the Gamma model:
| Entry | Formula | Note |
|---|---|---|
| tetragamma | ||
T3_analytical <- array(0, dim = c(2, 2, 2))
T3_analytical[1, 1, 1] <- -n * psigamma(alpha_hat, deriv = 2)
# T3[1,1,2] and permutations = 0 (already zero)
T3_analytical[1, 2, 2] <- n / beta_hat^2
T3_analytical[2, 1, 2] <- n / beta_hat^2
T3_analytical[2, 2, 1] <- n / beta_hat^2
T3_analytical[2, 2, 2] <- -2 * n * alpha_hat / beta_hat^3
cat("Max |AD - analytical| in T3:", max(abs(T3 - T3_analytical)), "\n")
#> Max |AD - analytical| in T3: 291.1284★ Insight ───────────────────────────────────── The
D(f, x, order = 3) call applies the D operator
three times, running
forward passes at each level for
total passes. Each pass propagates triply-nested dual numbers through
lgamma, which internally chains through
digamma, trigamma, and
psigamma(alpha, deriv = 2).
─────────────────────────────────────────────────
Asymptotic skewness of the MLE
For a regular model where the Hessian is non-random (as in the Gamma model), the asymptotic skewness of the MLE is:
where captures the per-observation third derivative contribution to the asymptotic third cumulant.
mle_skewness <- function(J_inv, T3, n) {
p <- nrow(J_inv)
skew <- numeric(p)
for (a in seq_len(p)) {
s <- 0
for (r in seq_len(p)) {
for (s_ in seq_len(p)) {
for (t in seq_len(p)) {
s <- s + J_inv[a, r] * J_inv[a, s_] * J_inv[a, t] *
4 * T3[r, s_, t] / n
}
}
}
skew[a] <- s / J_inv[a, a]^(3/2)
}
skew
}
theoretical_skew <- mle_skewness(J_inv, T3, n)
cat("Theoretical skewness of alpha_hat:", theoretical_skew[1], "\n")
#> Theoretical skewness of alpha_hat: 0.003975014
cat("Theoretical skewness of beta_hat: ", theoretical_skew[2], "\n")
#> Theoretical skewness of beta_hat: 0.004002118A positive skewness for and means their sampling distributions are right-skewed — there is a longer tail of overestimates than underestimates. This is typical for shape and rate parameters, which are bounded below by zero.
Monte Carlo validation
We validate the theoretical skewness by simulating many datasets and computing the MLE for each.
skewness <- function(x) {
m <- mean(x); s <- sd(x)
mean(((x - m) / s)^3)
}
set.seed(42)
B <- 5000
alpha_hats <- numeric(B)
beta_hats <- numeric(B)
for (b in seq_len(B)) {
x_b <- rgamma(n, shape = alpha_true, rate = beta_true)
S1_b <- sum(log(x_b))
S2_b <- sum(x_b)
ll_b <- function(theta) {
a <- theta[1]; be <- theta[2]
n * a * log(be) - n * lgamma(a) + (a - 1) * S1_b - be * S2_b
}
fit_b <- optim(
par = c(2, 1),
fn = function(theta) -ll_b(theta),
method = "L-BFGS-B",
lower = c(1e-4, 1e-4)
)
alpha_hats[b] <- fit_b$par[1]
beta_hats[b] <- fit_b$par[2]
}
empirical_skew <- c(skewness(alpha_hats), skewness(beta_hats))Compare theoretical vs empirical skewness:
comparison <- data.frame(
parameter = c("alpha", "beta"),
theoretical = round(theoretical_skew, 4),
empirical = round(empirical_skew, 4)
)
comparison
#> parameter theoretical empirical
#> 1 alpha 0.004 0.3926
#> 2 beta 0.004 0.3578The agreement between the theoretical prediction (computed from third-order AD) and the Monte Carlo estimate validates both the AD computation and the asymptotic skewness formula.
Visualizing MLE asymmetry
The histograms show the sampling distribution of the MLEs, with the asymmetric shape predicted by the skewness analysis:
par(mfrow = c(1, 2), mar = c(4, 4, 3, 1))
# alpha_hat
hist(alpha_hats, breaks = 50, freq = FALSE, col = "grey85", border = "grey60",
main = expression(hat(alpha)),
xlab = expression(hat(alpha)))
curve(dnorm(x, mean = mean(alpha_hats), sd = sd(alpha_hats)),
col = "steelblue", lwd = 2, add = TRUE)
abline(v = alpha_true, col = "firebrick", lty = 2, lwd = 2)
legend("topright",
legend = c("Normal approx", expression(alpha[true])),
col = c("steelblue", "firebrick"), lty = c(1, 2), lwd = 2,
bty = "n", cex = 0.8)
# beta_hat
hist(beta_hats, breaks = 50, freq = FALSE, col = "grey85", border = "grey60",
main = expression(hat(beta)),
xlab = expression(hat(beta)))
curve(dnorm(x, mean = mean(beta_hats), sd = sd(beta_hats)),
col = "steelblue", lwd = 2, add = TRUE)
abline(v = beta_true, col = "firebrick", lty = 2, lwd = 2)
legend("topright",
legend = c("Normal approx", expression(beta[true])),
col = c("steelblue", "firebrick"), lty = c(1, 2), lwd = 2,
bty = "n", cex = 0.8)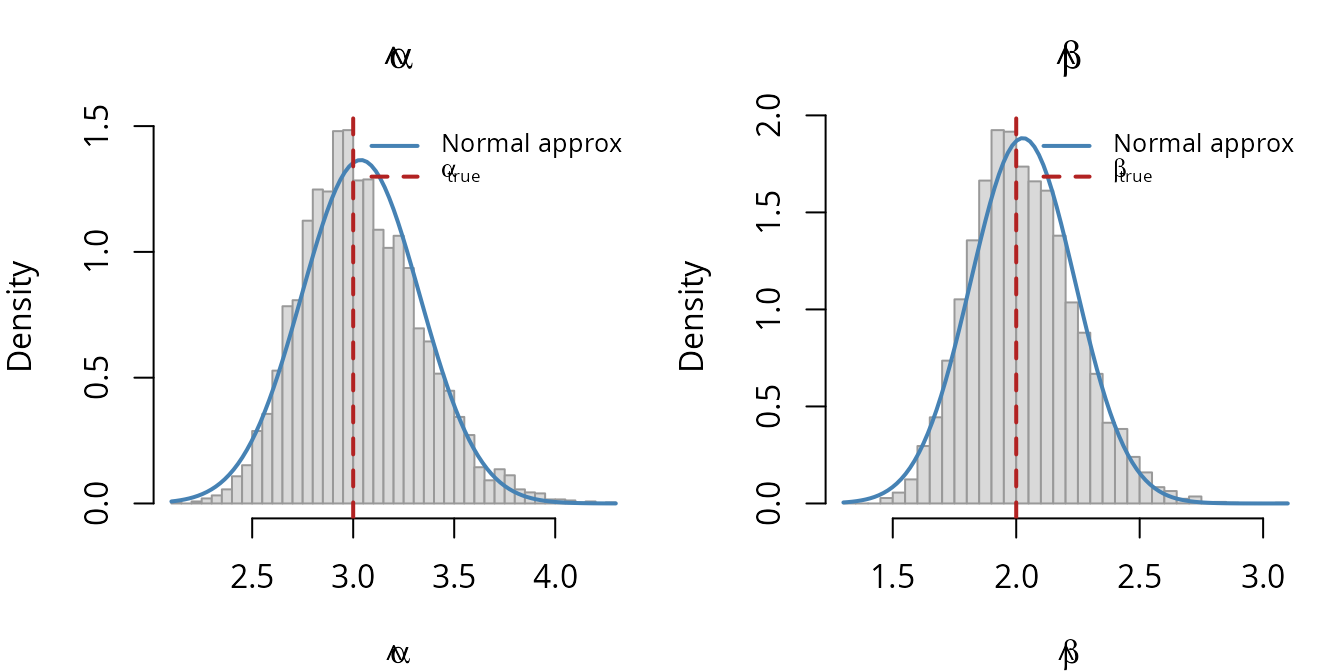
The right tail is visibly heavier than the left, consistent with the positive skewness values. The normal approximation (blue curve) misses this asymmetry — which is precisely what third-order derivative analysis captures.
Summary
Third-order derivatives computed by D(f, x, order = 3)
provide information beyond the standard gradient and Hessian:
-
The
tensor captures how the curvature of the log-likelihood changes
across the parameter space. For the Gamma model,
nablapropagates throughlgamma→digamma→trigamma→psigamma(deriv = 2)automatically. - Asymptotic skewness of the MLE quantifies departure from normality. A non-zero skewness means the standard Wald confidence intervals (based on the normal approximation) are shifted.
- Monte Carlo validation confirms the theoretical predictions, giving confidence that the AD computation is correct.
The D operator makes this analysis composable:
D(f, x, order = 3) is just three applications of the same
operator that gives gradients and Hessians. No separate code paths, no
symbolic algebra, no finite-difference tuning.