Introduction
The dfr.dist package provides a flexible framework for
working with survival distributions defined through their hazard
(failure rate) functions. Instead of choosing from a fixed
catalog of distributions, you directly specify the hazard function
itself, giving complete flexibility to model systems with complex,
time-varying failure patterns.
Why hazard-based parameterization?
Traditional approaches use parametric families (Weibull, exponential, log-normal) that impose strong assumptions on failure rate behavior. The hazard function provides a more intuitive parameterization for reliability:
- Constant hazard: Exponential distribution (memoryless failures)
- Increasing hazard: Wear-out phenomena
- Decreasing hazard: Burn-in or infant mortality
- Bathtub curve: Common in electronics and human mortality
Getting Started
library(dfr.dist)
library(algebraic.dist)
#>
#> Attaching package: 'algebraic.dist'
#> The following object is masked from 'package:grDevices':
#>
#> pdfCreating a DFR distribution
Use dfr_dist() to create a distribution from a hazard
function:
# Exponential distribution: constant hazard h(t) = lambda
exp_dist <- dfr_dist(
rate = function(t, par, ...) rep(par[1], length(t)),
par = c(lambda = 0.5)
)
print(exp_dist)
#> Dynamic failure rate (DFR) distribution with failure rate:
#> <srcref: file "" chars 3:10 to 3:53>
#> It has a survival function given by:
#> S(t|rate) = exp(-H(t,...))
#> where H(t,...) is the cumulative hazard function.
is_dfr_dist(exp_dist)
#> [1] TRUEThe rate function must accept:
-
t: time (scalar or vector) -
par: parameter vector -
...: additional arguments
Distribution Methods
All standard distribution functions are available:
Likelihood Model Interface
The dfr_dist class implements the
likelihood_model interface, enabling maximum likelihood
estimation with survival data.
Log-likelihood for survival data
For exact observations (failures at known times):
For right-censored observations (survived past time ):
Creating test data
# Simulate exact failure times from exponential(lambda=1)
set.seed(123)
true_lambda <- 1
n <- 50
times <- rexp(n, rate = true_lambda)
# Create data frame with standard survival format
# delta = 1 means exact observation, delta = 0 means censored
df_exact <- data.frame(t = times, delta = rep(1, n))
head(df_exact)
#> t delta
#> 1 0.84345726 1
#> 2 0.57661027 1
#> 3 1.32905487 1
#> 4 0.03157736 1
#> 5 0.05621098 1
#> 6 0.31650122 1Computing log-likelihood
dist <- dfr_dist(
rate = function(t, par, ...) rep(par[1], length(t)),
par = NULL # No default - must be supplied
)
ll <- loglik(dist)
# Evaluate at different parameter values
ll(df_exact, par = c(0.5)) # lambda = 0.5
#> [1] -62.91663
ll(df_exact, par = c(1.0)) # lambda = 1.0 (true value)
#> [1] -56.51854
ll(df_exact, par = c(2.0)) # lambda = 2.0
#> [1] -78.37973The log-likelihood should be highest near the true parameter value.
Score function (gradient)
The score function is the gradient of the log-likelihood with respect to parameters. It’s computed numerically by default:
Hessian of log-likelihood
H_ll <- hess_loglik(dist)
hess <- H_ll(df_exact, par = c(1.0))
hess # Should be negative (concave at maximum)
#> [,1]
#> [1,] -50Maximum Likelihood Estimation
The fit() function provides MLE estimation:
solver <- fit(dist)
# Find MLE starting from initial guess
result <- solver(df_exact, par = c(0.5), method = "BFGS")
# Extract fitted parameters
params(result)
#> [1] 0.8846654
# Compare to analytical MLE: lambda_hat = n / sum(t)
analytical_mle <- n / sum(times)
c(fitted = params(result), analytical = analytical_mle, true = true_lambda)
#> fitted analytical true
#> 0.8846654 0.8846654 1.0000000Working with censored data
Real survival data often includes censoring. Here’s an example with mixed data:
# Some observations are censored (patient still alive at study end)
df_mixed <- data.frame(
t = c(1, 2, 3, 4, 5, 6, 7, 8),
delta = c(1, 1, 1, 0, 0, 1, 1, 0) # 0 = censored
)
ll <- loglik(dist)
# Fit with censored data
solver <- fit(dist)
result <- solver(df_mixed, par = c(0.5), method = "BFGS")
#> Warning in log(h_exact): NaNs produced
#> Warning in log(h_exact): NaNs produced
#> Warning in log(h_exact): NaNs produced
#> Warning in log(h_exact): NaNs produced
#> Warning in log(h_exact): NaNs produced
#> Warning in log(h_exact): NaNs produced
#> Warning in log(h_exact): NaNs produced
params(result)
#> [1] 0.1388889Example: Weibull MLE
# Create Weibull DFR
weibull <- dfr_dist(
rate = function(t, par, ...) {
k <- par[1]
sigma <- par[2]
(k / sigma) * (t / sigma)^(k - 1)
}
)
# Simulate Weibull data (shape=2, scale=3)
set.seed(456)
true_shape <- 2
true_scale <- 3
n <- 100
# Use inverse CDF sampling
u <- runif(n)
weibull_times <- true_scale * (-log(u))^(1/true_shape)
df_weibull <- data.frame(t = weibull_times, delta = rep(1, n))
# Fit
solver <- fit(weibull)
result <- solver(df_weibull, par = c(1.5, 2.5), method = "BFGS")
c(fitted_shape = params(result)[1], true_shape = true_shape)
#> fitted_shape true_shape
#> 1.92518 2.00000
c(fitted_scale = params(result)[2], true_scale = true_scale)
#> fitted_scale true_scale
#> 2.788113 3.000000Custom Hazard Functions
The real power of dfr.dist is modeling complex,
non-standard hazard patterns.
Bathtub hazard
A classic bathtub curve has three phases: 1. Infant mortality: High initial failure rate that decreases 2. Useful life: Low, relatively constant failure rate 3. Wear-out: Increasing failure rate as components age
# h(t) = a * exp(-b*t) + c + d * t^k
# Three components: infant mortality + baseline + wear-out
bathtub <- dfr_dist(
rate = function(t, par, ...) {
a <- par[1] # infant mortality magnitude
b <- par[2] # infant mortality decay rate
c <- par[3] # baseline hazard (useful life)
d <- par[4] # wear-out coefficient
k <- par[5] # wear-out exponent
a * exp(-b * t) + c + d * t^k
},
par = c(a = 1, b = 2, c = 0.02, d = 0.001, k = 2)
)
# Plot the hazard function
t_seq <- seq(0.01, 15, length.out = 200)
h <- hazard(bathtub)
plot(t_seq, sapply(t_seq, h), type = "l",
xlab = "Time", ylab = "Hazard rate",
main = "Bathtub hazard curve")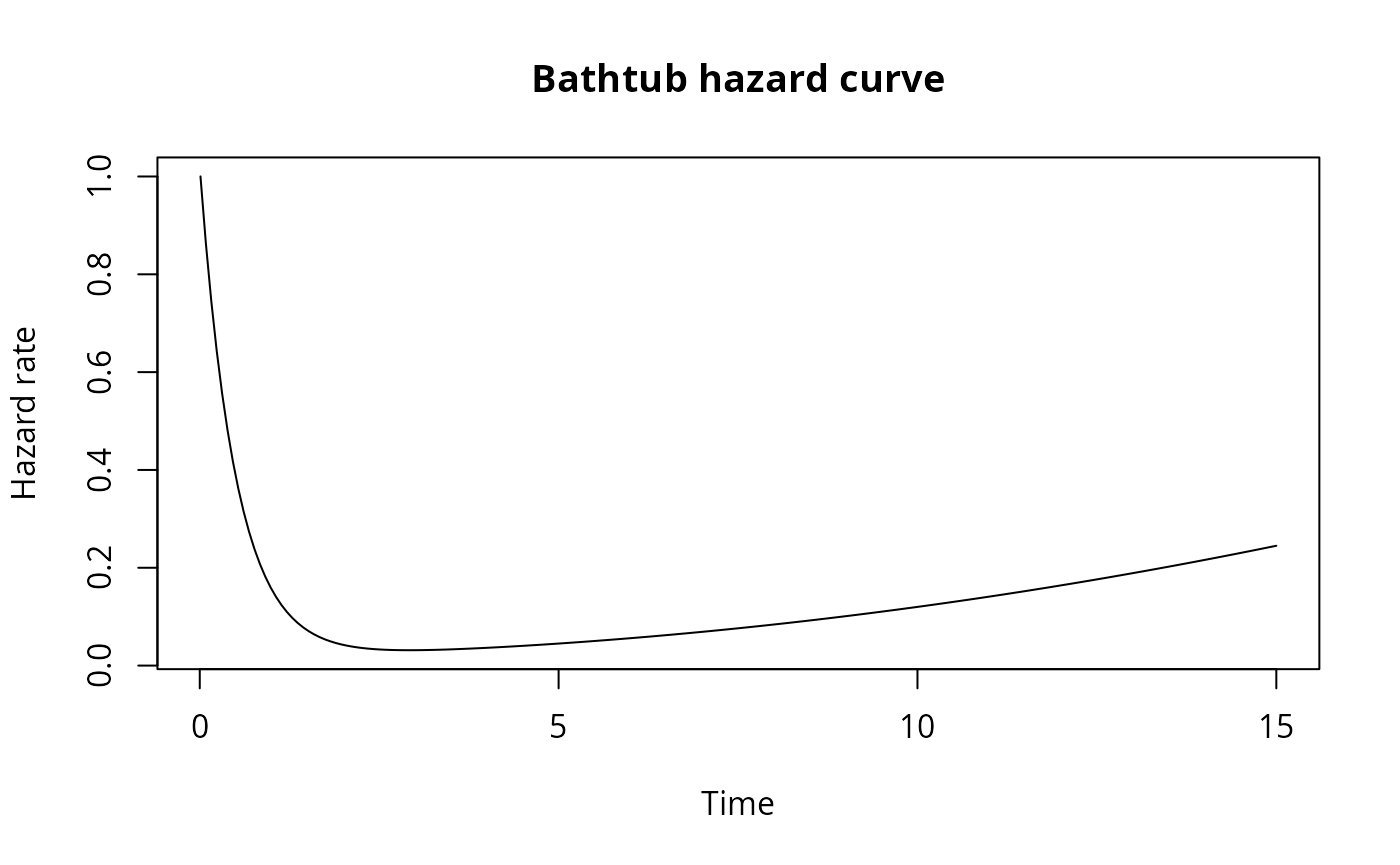
Time-covariate interaction
Hazards can depend on covariates that modify the time effect:
# Proportional hazards with covariate x
# h(t, x) = h0(t) * exp(beta * x)
# where h0(t) = Weibull baseline
ph_model <- dfr_dist(
rate = function(t, par, x = 0, ...) {
k <- par[1]
sigma <- par[2]
beta <- par[3]
baseline <- (k / sigma) * (t / sigma)^(k - 1)
baseline * exp(beta * x)
},
par = c(shape = 2, scale = 3, beta = 0.5)
)
h <- hazard(ph_model)
# Hazard for different covariate values
h(2, x = 0) # Baseline
#> shape
#> 0.4444444
h(2, x = 1) # Higher risk group
#> shape
#> 0.732765Integration with algebraic.dist
The dfr_dist class inherits from
algebraic.dist classes, providing access to additional
functionality:
Summary
The dfr.dist package provides:
- Flexible specification: Define distributions through hazard functions
- Complete distribution interface: hazard, survival, CDF, PDF, quantiles, sampling
- Likelihood model support: Log-likelihood, score, Hessian for MLE
- Censoring support: Handle exact and right-censored survival data
- Numerical integration: Automatic computation of cumulative hazard
This makes it ideal for:
- Custom reliability models
- Survival analysis with non-standard hazard patterns
- Maximum likelihood estimation of hazard function parameters
- Simulation studies with flexible failure distributions