Relaxed Candidate Set Models for Masked Data in Series Systems
Abstract
We develop likelihood-based inference methods for series systems with masked failure data when the traditional conditions governing candidate set formation are relaxed. While existing methods require that masking be non-informative (Condition C2) and parameter-independent (Condition C3), practical diagnostic systems often violate these assumptions. We derive the likelihood under various relaxation scenarios, establish identifiability conditions, and compare Fisher information under standard versus relaxed models. Our analysis reveals that informative masking, when properly modeled, can paradoxically improve estimation efficiency by providing additional information about the failed component. Simulation studies quantify the bias from incorrectly assuming standard conditions when masking is informative (C2 violation) or parameter-dependent (C3 violation), and demonstrate that the framework extends to Weibull series systems. We implement these methods in the mdrelax R package.
Keywords: Series systems, masked data, reliability estimation, informative masking, candidate sets, Fisher information, maximum likelihood estimation
1 Introduction
Estimating the reliability of individual components in a series system presents a fundamental challenge in reliability engineering: system-level failure data is observable, but component-level failure causes are often masked. When a series system fails, diagnostic procedures may identify only a candidate set of components that could have caused the failure, rather than pinpointing the exact failed component [7]. This masking, combined with right-censoring of system lifetimes, complicates statistical inference about component reliability parameters.
Prior work on masked data in series systems has established a tractable likelihood framework under three conditions [6]:
-
•
C1: The failed component is always contained in the candidate set.
-
•
C2: Masking is non-informative—conditional on the failure time and candidate set, each component in the candidate set is equally likely to have failed.
-
•
C3: The masking mechanism does not depend on the system parameters .
Under these conditions, the likelihood has a simple closed form that enables efficient maximum likelihood estimation (MLE). However, practical diagnostic systems may violate C2 and C3:
-
•
Experienced technicians may preferentially include components that “seem likely” to have failed based on failure time characteristics, violating C2.
-
•
Diagnostic algorithms based on reliability rankings may systematically favor certain components, with the ranking depending on the true parameters, violating C3.
This paper develops the theoretical and computational framework for likelihood-based inference when C2 and/or C3 are relaxed while maintaining C1. Our contributions are:
-
1.
General likelihood framework. We derive the likelihood under C1 alone, showing how informative and parameter-dependent masking modify the standard likelihood structure (Section 3).
-
2.
Practical masking models. We introduce the rank-based informative masking model and the Bernoulli candidate set model with KL-divergence constraints, which provide interpretable parameterizations of non-standard masking (Section 3).
-
3.
Identifiability analysis. We establish conditions under which parameters remain identifiable when standard conditions fail, including the surprising result that informative masking can improve identifiability in certain cases (Section 4).
-
4.
Efficiency comparison. We derive the Fisher information matrix under relaxed conditions for exponential series systems, enabling precise comparison of estimation efficiency (Section 4).
-
5.
Simulation studies. We quantify the bias from incorrectly assuming C2 when masking is informative, and demonstrate the improved estimation achievable when the masking structure is properly modeled (Section 5).
The remainder of this paper is organized as follows. Section 2 reviews series systems, masked data, and the standard C1-C2-C3 likelihood. Section 3 develops the likelihood under relaxed conditions. Section 4 analyzes identifiability and Fisher information. Section 5 presents simulation studies. Section 6 discusses practical implications, and Section 7 concludes.
2 Background
2.1 Series System Model
Consider a series system composed of components. The lifetime of the -th system is
| (1) |
where denotes the lifetime of the -th component in the -th system. Component lifetimes are assumed independent with parametric distributions indexed by ; the full parameter vector is .
Definition 2.1 (Component Distribution Functions).
For component with parameter :
| (2) | |||||
| (3) | |||||
| (4) |
For the series system, these functions combine as follows:
Theorem 2.2 (Series System Distribution Functions).
The series system has:
| (5) | ||||
| (6) | ||||
| (7) |
The proof follows from the independence of component lifetimes and standard arguments [6].
2.2 Component Cause of Failure
Let denote the index of the component that caused system to fail. Since the system fails when the first component fails, .
Theorem 2.3 (Joint Distribution of ).
The joint distribution of system lifetime and component cause of failure is:
| (8) |
The proof follows from the definition of the series system minimum and the independence of component lifetimes; see [6] for details.
Corollary 2.4 (Conditional Failure Probability).
Given that the system failed at time , the probability that component caused the failure is:
| (9) |
This follows immediately from Theorem 2.3 and Bayes’ theorem; see [6].
This probability plays a central role in masked data analysis, as it represents the “true” probability that each component failed, which the masking mechanism partially obscures.
2.3 Masked Data Structure
Definition 2.5 (Observed Data).
For each system , we observe:
-
•
: Right-censored system lifetime,
-
•
: Event indicator ( if failure observed, if censored),
-
•
: Candidate set (only observed when ).
The latent (unobserved) variables are:
-
•
: Index of failed component,
-
•
: Component failure times.
2.4 Traditional Conditions C1, C2, C3
The existing literature [7, 8, 4] establishes tractable likelihood-based inference under three conditions:
Condition 1 (C1: Failed Component in Candidate Set).
The candidate set always contains the failed component:
| (10) |
Condition 2 (C2: Non-Informative Masking).
Given the failure time and that the failed component is in a candidate set , the probability of observing does not depend on which component in failed:
| (11) |
for all .
Condition 3 (C3: Parameter-Independent Masking).
The masking probabilities do not depend on the system parameters:
| (12) |
where does not depend on .
2.5 Likelihood Under C1, C2, C3
Under all three conditions, the likelihood admits a tractable form:
Theorem 2.6 (Likelihood Under C1-C2-C3).
Under Conditions C1, C2, and C3, the likelihood contribution from an uncensored observation is proportional to:
| (13) |
For a censored observation with lifetime :
| (14) |
The proof proceeds by summing over and applying C1, C2, C3 in sequence to factor and then eliminate the masking probability; see [6] for the full derivation.
The complete log-likelihood for independent systems is:
| (15) |
2.6 Related Work
The masked data problem in series systems was introduced by Usher and Hodgson [7], who developed MLE methods for exponential components. Usher et al. [8] extended this to Weibull components with exact maximum likelihood. Guo et al. [4] (Guo et al.) provided simulation studies validating the approach under various masking scenarios.
The informative censoring literature in survival analysis [5, 3] addresses related issues where the censoring mechanism depends on covariates or outcomes. However, the candidate set structure in masked data creates a distinct problem not fully addressed by standard informative censoring methods.
The competing risks framework [1] provides another perspective, viewing component failures as competing causes of system failure. However, standard competing risks methods assume the cause is observed, whereas masked data only provides partial information through candidate sets.
Our work extends the C1-C2-C3 framework by explicitly modeling departures from C2 and C3, providing both theoretical analysis and practical estimation methods.
3 Relaxed Candidate Set Models
We now develop the likelihood framework when conditions C2 and/or C3 are relaxed while maintaining C1. The key insight is that the general likelihood structure remains tractable—it simply requires modeling the masking mechanism explicitly rather than treating it as a nuisance.
3.1 General Likelihood Under C1
Theorem 3.1 (Likelihood Under C1 Alone).
Under Condition C1 alone, the likelihood contribution from an uncensored observation is:
| (16) |
Proof.
Under C1, when . Therefore, summing over :
| (17) | ||||
| (18) |
Remark 3.1 (Comparison with C1-C2-C3).
Under C2, the masking probability can be factored out of the sum since it is constant over . Under C3, it can be dropped since it does not depend on . When either condition fails, the masking probabilities remain inside the sum and may depend on both and , fundamentally changing the inference problem.
3.2 Relaxing C2: Informative Masking
When C2 is violated but C1 and C3 hold, the masking probability can vary with .
Definition 3.2 (Informative Masking).
Let for . The masking is informative if varies with .
Theorem 3.3 (Likelihood Under C1 and C3 (Relaxed C2)).
Under C1 and C3, the likelihood contribution is:
| (19) |
where does not depend on (by C3).
When is known, the likelihood remains tractable. The masking probabilities act as weights on the hazard contributions from each candidate.
3.2.1 Rank-Based Informative Masking
A practical model for informative masking assigns inclusion probabilities based on component failure ranks rather than absolute times.
Definition 3.4 (Rank-Based Masking).
Let denote the rank of component ’s failure time among , where rank 1 corresponds to the earliest failure (the actual failed component).
The probability that component is in the candidate set is:
| (20) |
where controls the decay rate and is the maximum inclusion probability for non-failed components.
Remark 3.2 (Limiting Behavior).
-
•
As : All non-failed components have probability (uninformative within the non-failed set).
-
•
As : Only the failed component and rank-2 component have non-zero probabilities.
This model captures the intuition that components failing “nearly at the same time” as the actual failure are more likely to be included in the candidate set.
3.2.2 General Bernoulli Candidate Set Model
The most general Bernoulli model for candidate set formation allows the inclusion probability of each component to depend on which component actually failed.
Definition 3.5 (General Bernoulli Model).
Let denote the probability that component is included in the candidate set given that component failed:
| (21) |
Under C1, we require for all . These probabilities can be organized into an matrix :
| (22) |
where the entry is .
Remark 3.3 (Time-Independence Assumption).
The most general Bernoulli model would allow to depend on the failure time as well as the failed component . We simplify by assuming time-independence: for all . This is a reasonable assumption when the masking mechanism depends on which component failed but not on when the failure occurred. Time-dependent models are left to future work.
Remark 3.4 (Condition C2 in Terms of ).
Condition C2 holds if and only if each row of has constant off-diagonal entries, i.e., for all . Relaxing C2 allows each column to have different values, meaning the masking mechanism “knows” something about which component failed.
The probability of observing candidate set given that component failed is:
| (23) |
Theorem 3.6 (Likelihood Under General Bernoulli Model).
Under the general Bernoulli model with C1 (and C3), the likelihood contribution from an uncensored observation is:
| (24) |
where is given by (23).
Remark 3.5 (Nuisance Parameters).
The off-diagonal entries of constitute nuisance parameters that must be estimated alongside the rate parameters (for exponential components). The total parameter count is .
3.2.3 Simplified Bernoulli Model (C2 Satisfied)
A special case assumes the inclusion probabilities do not depend on :
Definition 3.7 (Simplified Bernoulli Model).
Each component is included in the candidate set independently with probability , subject to C1 (failed component always included):
| (25) |
This model satisfies C2 since the masking probability does not depend on which component actually failed.
Under this simplified model, the probability of observing candidate set given is:
| (26) |
Proposition 3.8 (Likelihood Under Simplified Bernoulli Model).
Under the simplified Bernoulli model with C1, C2 and known probabilities , the likelihood contribution is:
| (27) |
where
| (28) |
is the probability of observing given that failed. Note that is the same for all (by C2), so it factors out and the likelihood reduces to the C1-C2-C3 form up to a constant.
3.2.4 KL-Divergence Constrained Models
To systematically study deviations from the standard C1-C2-C3 model, we can parameterize informative masking by its distance from the baseline:
Definition 3.9 (KL-Divergence from Baseline).
Let denote the baseline Bernoulli model satisfying C1-C2-C3, where the failed component has probability 1 and all others have probability .
For a given target KL-divergence , we seek a masking probability vector satisfying:
-
1.
for the failed component (C1),
-
2.
,
-
3.
(same expected candidate set size).
When , we recover (the C1-C2-C3 model). As increases, becomes more informative about which component failed. This provides a controlled framework for studying the effects of departures from C2.
3.3 Relaxing C3: Parameter-Dependent Masking
When C3 is violated, the masking probability depends on .
Theorem 3.10 (Likelihood Under C1 and C2 (Relaxed C3)).
Under C1 and C2, the likelihood contribution is:
| (29) |
where is the (common) masking probability for any , now depending on .
Proof.
By C2, we can factor out the masking probability since it is constant over :
| (30) | ||||
| (31) |
Remark 3.6 (Nuisance Parameters).
When has a known functional form, it contributes to the likelihood and affects the MLE. If the form is unknown, additional modeling assumptions or profile likelihood approaches may be needed.
3.3.1 Failure-Probability-Weighted Masking
A natural way for masking to depend on is through the conditional failure probabilities:
Definition 3.11 (Failure-Probability-Weighted Masking).
The probability that component is in the candidate set depends on its posterior failure probability:
| (32) |
for some function with as .
This models diagnosticians who are more likely to include components with higher failure probabilities given the observed failure time. The function controls the sensitivity of masking to these probabilities.
3.3.2 Power-Weighted Hazard Model
A particularly tractable form uses hazard rates raised to a power :
Definition 3.12 (Power-Weighted Masking).
The inclusion probability for component is proportional to its hazard rate raised to power :
| (33) |
Remark 3.7 (Limiting Cases).
-
•
: Uniform distribution over all components (uninformative).
-
•
: Inclusion proportional to hazard (posterior failure probability).
-
•
: Assigns probability 1 to the component with highest hazard rate (maximally informative).
For exponential components with rates , the hazards are constant, so the inclusion probability for component becomes , independent of .
Remark 3.8 (Relaxing C1).
Under power-weighted masking with large , the true failed component has high posterior probability of being included even without enforcing C1. This suggests that for “maximally informative” masking models, the strict requirement that (C1) may be relaxed to a softer constraint.
Remark 3.9 (Model Misspecification Risk).
Parameter-dependent masking models like (33) represent strong assumptions about the data-generating process. If the assumed masking mechanism is incorrect, the resulting MLEs may be severely biased.
For example, if data are generated under the simple Bernoulli model (C1-C2-C3) but analyzed under the power-weighted model with , the estimator will attribute variation in candidate sets to hazard rate differences rather than random masking, leading to biased rate estimates.
This contrasts with the conservative C1-C2-C3 approach: when C2 and C3 hold, the masking mechanism is non-informative and can be “integrated out,” making inference robust to the specific masking probabilities. When relaxing these conditions, the analyst trades robustness for potential efficiency gains, but only when the assumed masking model is correct.
3.4 The General Case: Both C2 and C3 Relaxed
When both C2 and C3 are relaxed, the likelihood takes the fully general form from Theorem 3.1:
| (34) |
Estimation in this general case requires either:
-
1.
A fully specified parametric model for , or
-
2.
Sensitivity analysis over plausible masking mechanisms, or
-
3.
Nonparametric or semiparametric approaches that avoid specifying the masking mechanism.
In practice, the most common scenario is relaxed C2 with C3 maintained (informative but parameter-independent masking), which we focus on in the simulation studies.
3.5 Simulation Evidence: Robustness of Relaxed C2
We conducted simulation studies to evaluate the practical implications of model choice when C2 may or may not hold. The key question: What is the cost of using the more flexible relaxed-C2 model when C2 actually holds?
3.5.1 Simulation Design
We consider an exponential series system with components and true parameters , . Each scenario uses observations with right-censoring time (moderate censoring).
- Scenario 1:
-
Data generated under C1-C2-C3 (), analyzed with C1-C2-C3 model. (Baseline)
- Scenario 2b:
-
Data generated under C1-C2-C3 (), analyzed with relaxed-C2 model using known .
- Scenario 3:
-
Data generated under relaxed C2 ( asymmetric), analyzed with C1-C2-C3 model. (Misspecified)
- Scenario 4b:
-
Data generated under relaxed C2 ( asymmetric), analyzed with relaxed-C2 model using known .
For the asymmetric matrix, we use (component 1 very likely included when component 2 fails) and (component 2 unlikely when component 1 fails).
3.5.2 Results
| Scenario | Model | Rel. Bias | Rel. Bias | RMSE | RMSE |
|---|---|---|---|---|---|
| 1 (C2 holds) | C1-C2-C3 | 0.7% | 1.6% | 9.7% | 7.2% |
| 2b (C2 holds) | Relaxed C2 (known ) | 0.7% | 1.6% | 9.6% | 7.2% |
| 3 (C2 violated) | C1-C2-C3 | 109% | 53% | 110% | 54% |
| 4b (C2 violated) | Relaxed C2 (known ) | 2.2% | 0.0% | 10.7% | 7.2% |
3.5.3 Interpretation
-
1.
Relaxed C2 is safe when C2 holds (Scenarios 1 vs. 2b): Using the more flexible relaxed-C2 model on data that satisfies C2 incurs essentially no efficiency penalty. Both bias and RMSE are virtually identical.
-
2.
Misspecification is catastrophic (Scenario 3): Fitting the C1-C2-C3 model when C2 is violated produces severe bias—over 100% for and for . The model misattributes informative masking to component failure rates.
-
3.
Correct model recovers parameters (Scenario 4b): When the relaxed-C2 model is used with the correct , estimates are nearly unbiased with reasonable variance.
Remark 3.10 (Practical Implications).
These results support a conservative modeling strategy: when the masking mechanism is uncertain, use the relaxed-C2 model with an estimated or hypothesized matrix. If C2 actually holds, little is lost. If C2 is violated, severe bias is avoided.
However, jointly estimating and from data alone poses identifiability challenges. In practice, should be either: (i) estimated from auxiliary data or expert knowledge, (ii) constrained to a lower-dimensional structure, or (iii) subjected to sensitivity analysis.
3.5.4 Identifiability of Joint Estimation
Additional simulations reveal that the difficulty with joint estimation of and is not a finite-sample problem. Even with observations, the joint MLE exhibits persistent bias:
| Estimation Method | ||
|---|---|---|
| Joint (, ) | 1.62 | 1.44 |
| Known | 0.97 | 2.08 |
| True values | 1.00 | 2.00 |
The joint estimator consistently converges to with (true: 0.10), regardless of sample size. This indicates fundamental non-identifiability: different combinations of yield similar likelihoods.
Notably, the total hazard remains well-identified ( vs. true 3.00), but individual components are confounded with the off-diagonal elements of .
Remark 3.11 (Implications for Practice).
This non-identifiability result has important practical implications:
-
1.
If can be estimated from auxiliary information (expert knowledge, pilot studies, or the masking process itself), the relaxed-C2 model provides excellent estimates.
-
2.
If is completely unknown, the analyst faces a choice: (a) assume C2 holds and use the simpler model (risking bias if C2 is violated), or (b) impose structural constraints on (e.g., symmetry, sparsity) to achieve identifiability.
-
3.
Sensitivity analysis over plausible matrices may reveal how conclusions depend on the assumed masking mechanism.
4 Identifiability and Fisher Information
We now analyze identifiability conditions and derive the Fisher information matrix under relaxed conditions, focusing on exponential series systems for tractability.
4.1 Identifiability Under C1-C2-C3
Definition 4.1 (Identifiability).
A parameter is identifiable if for any with , there exists some data configuration such that
| (35) |
Theorem 4.2 (Identifiability Under C1-C2-C3).
Under C1, C2, and C3, the parameter is identifiable if and only if the following condition holds: For each pair of components , there exists at least one observed candidate set such that exactly one of or holds (i.e., the components do not always co-occur in candidate sets).
Proof.
The log-likelihood contribution from an uncensored observation is:
| (36) |
Sufficiency: If components and appear in different candidate sets, then information about can be obtained from observations where but , and vice versa. Combined with the survival term (which depends on all parameters), this provides sufficient variation to identify individual parameters.
Necessity: If components and always co-occur in every candidate set, the hazard sum always contains as an inseparable unit. The survival term provides information only about . Thus, any reparametrization preserving both and yields the same likelihood, demonstrating non-identifiability. ∎
4.2 Block Non-Identifiability
A particularly important case arises when components form blocks that always appear together:
Theorem 4.3 (Block Non-Identifiability).
Suppose components are partitioned into blocks such that for every observed candidate set :
-
(i)
For each block : either or , and
-
(ii)
If the failed component , then .
Then for exponential components with rates , only the block sums are identifiable.
Proof.
Under the exponential model with constant hazards, the likelihood becomes:
| (37) |
The survival term depends only on . For the hazard sum, under the block structure, each candidate set is a union of complete blocks. Thus:
| (38) |
Any reparametrization that preserves yields the same likelihood, hence individual within blocks are not identifiable. ∎
Example 4.1 (Three-Component Block Model).
Consider a 3-component system where the diagnostic tool can only distinguish:
-
•
Components 1 and 2 share a circuit board (block ),
-
•
Component 3 is separate (block ).
Candidate sets are either , , or . The MLE satisfies:
| (39) | ||||
| (40) |
but individual are not unique.
4.3 Improved Identifiability with Informative Masking
Surprisingly, relaxing C2 can improve identifiability:
Theorem 4.4 (Improved Identifiability with Informative Masking).
Under C1 and C3 with known informative masking probabilities , identifiability can be improved relative to the C1-C2-C3 case. Specifically, if components and always co-occur in candidate sets (violating the identifiability condition of Theorem 4.2), they become identifiable if there exists a candidate set with such that for some .
Proof.
Under C1-C2-C3 with non-informative masking, if components and always co-occur, the hazard sum contains only the unweighted sum , making individual hazards non-identifiable.
Under informative masking with known weights , the likelihood contribution becomes:
| (41) |
The hazard sum now involves the weighted combination . If , this provides one equation involving and with unequal coefficients.
Combined with the survival term (which contributes through the system hazard), we have two linearly independent equations:
| (42) | ||||
| (43) |
When , this system has a unique solution, establishing identifiability of individual hazards. ∎
Remark 4.1.
Informative masking can paradoxically help estimation when the masking structure is known, because it provides additional information about which component likely failed.
4.4 Fisher Information for Exponential Series Systems
We now derive closed-form expressions for the Fisher information matrix, specializing to exponential components.
4.4.1 Exponential Series Model
For exponential components with rates :
| (44) | ||||
| (45) | ||||
| (46) |
4.4.2 Fisher Information Under C1-C2-C3
Theorem 4.5 (FIM Under C1-C2-C3).
For the exponential series system under C1, C2, C3, the observed Fisher information matrix has elements:
| (47) |
Proof.
The log-likelihood for an uncensored observation is:
| (48) |
The first derivatives (score) are:
| (49) |
The second derivatives are:
| (50) |
The observed FIM is the negative Hessian, giving the result. ∎
Remark 4.2.
The FIM depends on the candidate sets but not on the failure times (for exponential components). This reflects the memoryless property of the exponential distribution.
4.4.3 Fisher Information Under Relaxed C2
Theorem 4.6 (FIM Under Informative Masking).
Under C1, C3, and informative masking with known weights , the observed Fisher information matrix for exponential components is:
| (51) |
Proof.
The log-likelihood contribution is:
| (52) |
The score is:
| (53) |
The Hessian is:
| (54) |
4.5 Efficiency Comparison
Theorem 4.7 (Relative Efficiency).
Let and denote the Fisher information matrices under C1-C2-C3 and C1-C3 (informative masking) respectively. Then:
-
(a)
If for all (uniform weighting), then .
-
(b)
If masking is highly informative (concentrating weight on one component), can exceed for that component’s parameter.
Proof.
(a) Under C1-C2-C3 (non-informative masking), the FIM element is:
| (55) |
Under C1-C3 with uniform weights for all :
| (56) | ||||
| (57) | ||||
| (58) |
(b) Suppose for component and for all in . Then:
| (59) |
This concentrates all information on , which can exceed when since the denominator under C1-C2-C3 is . ∎
Remark 4.3 (Practical Implications).
Informative masking can either help or hurt estimation:
-
•
Helps when the masking structure is known and aligned with what we want to estimate.
-
•
Hurts if masking is informative but we incorrectly assume C2 (non-informative), leading to model misspecification bias.
4.6 Estimation Under Model Misspecification
Theorem 4.8 (Bias from C2 Misspecification).
Suppose the true model is C1-C3 with informative masking , but estimation is performed assuming C1-C2-C3 (non-informative masking). The resulting MLE is generally biased, with bias depending on the correlation between and the hazard ratios .
Proof.
The score under the assumed (wrong) C1-C2-C3 model is:
| (60) |
The true score under C1-C3 (informative masking) is:
| (61) |
At the true parameter , the true score has expectation zero: .
The misspecified score has expectation:
| (62) |
This differs from zero when the masking weights are correlated with the hazard ratios. Specifically, define the “effective” weight under the true model. The MLE under the wrong model solves , yielding that satisfies:
| (63) |
When for components with larger , the misspecified model overestimates components that are more likely to be in candidate sets, producing systematic bias. ∎
Theorem 4.9 (Bias from C3 Misspecification).
Suppose the true model has parameter-dependent masking (C3 violated) with , but estimation is performed assuming C1-C2-C3 (ignoring the -dependence). The resulting MLE is generally biased, unless the masking probability is locally constant in near the true parameter value.
Proof.
Under the true model (relaxed C3), the log-likelihood contribution is:
| (64) |
The misspecified model drops the masking term:
| (65) |
The misspecified score omits , which is non-zero when masking depends on . Setting the wrong score to zero yields a pseudo-true parameter satisfying:
| (66) |
which differs from unless at . ∎
These results motivate the simulation studies in Section 5, which quantify the bias under both C2 and C3 misspecification scenarios.
5 Simulation Studies
We present simulation studies to (1) validate MLE performance under the C1-C2-C3 Bernoulli masking model, (2) quantify the bias from incorrectly assuming C2 when masking is informative, and (3) investigate identifiability issues arising from correlated candidate sets.
5.1 Experimental Design
5.1.1 System Configuration
We consider exponential series systems with components and true rate parameters:
| (67) |
These values represent a system where component 3 has the highest failure rate (and thus contributes most to system failures), while component 1 is most reliable.
5.1.2 Data Generation
For each simulation replicate:
-
1.
Generate component failure times for and .
-
2.
Compute system failure times and identify failed components .
-
3.
Apply right-censoring at time (chosen to achieve approximately 20% censoring) to obtain observed lifetimes and indicators .
-
4.
Generate candidate sets using the specified masking model.
5.1.3 Masking Models
We examine three masking scenarios:
-
1.
C1-C2-C3 (Baseline): Bernoulli model with for all non-failed components.
-
2.
Informative masking (Rank-based): Masking probabilities depend on component failure time ranks, parameterized by informativeness parameter .
-
3.
Correlated candidate sets: Candidate set indicators have correlation .
5.1.4 Performance Metrics
We evaluate:
-
•
Bias:
-
•
Root mean squared error (RMSE):
-
•
Coverage probability: Proportion of 95% confidence intervals containing
-
•
RMSE ratio:
5.2 Study 1: MLE Performance Under Bernoulli Masking
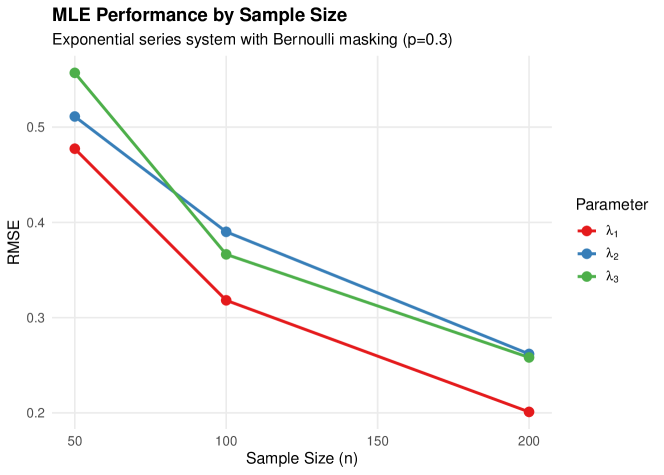
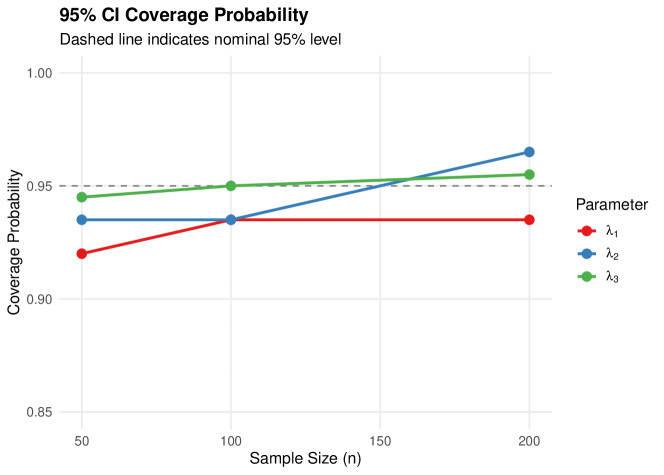
We first validate MLE performance under the correctly specified C1-C2-C3 Bernoulli masking model across sample sizes with Monte Carlo replicates.
5.2.1 Results
Table 2 presents the estimation results.
| Parameter | Bias | RMSE | Coverage | Mean CI Width | |
|---|---|---|---|---|---|
| 50 | 0.017 | 0.477 | 0.920 | 1.727 | |
| 0.007 | 0.511 | 0.935 | 1.952 | ||
| 0.085 | 0.557 | 0.945 | 2.197 | ||
| 100 | 0.016 | 0.318 | 0.935 | 1.175 | |
| 0.055 | 0.390 | 0.935 | 1.385 | ||
| 0.366 | 0.950 | 1.519 | |||
| 200 | 0.201 | 0.935 | 0.825 | ||
| 0.008 | 0.262 | 0.965 | 0.965 | ||
| 0.258 | 0.955 | 1.066 |
Notes. Results based on 200 Monte Carlo replications. True parameters: , , . Bernoulli masking with , censoring proportion .
Key findings from Study 1:
-
1.
Consistency: Bias is small relative to RMSE at all sample sizes, indicating approximate unbiasedness.
-
2.
Convergence: RMSE decreases from approximately 0.5 at to 0.2–0.3 at , consistent with -rate convergence.
-
3.
Coverage: 95% CI coverage ranges from 92.0% to 96.5%, close to the nominal level, validating the Fisher information-based standard errors.
-
4.
Component effects: Components with higher true rates () have slightly larger absolute RMSE but similar relative performance.
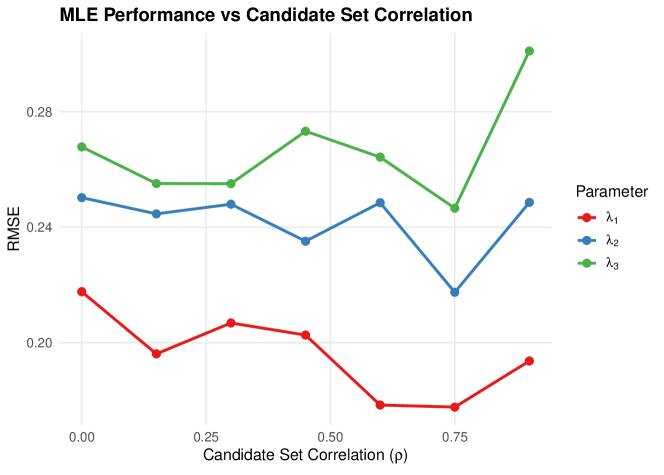
5.3 Study 2: Misspecification Bias Analysis
We quantify the bias from incorrectly assuming C1-C2-C3 when masking is actually informative. Data is generated with rank-based informative masking (informativeness parameter ), then analyzed using both the correct model and the misspecified C2 model.
5.3.1 Results
Table 3 compares bias under correct versus misspecified models.
| Parameter | Bias (Correct) | Bias (Misspec.) | RMSE Ratio | |
|---|---|---|---|---|
| 0 | 1.019 | |||
| 0.027 | 0.024 | 1.090 | ||
| 0.105 | 1.013 | |||
| 1 | 0.999 | |||
| 1.031 | ||||
| 0.192 | 0.146 | 0.944 | ||
| 5 | 1.002 | |||
| 0.010 | 1.031 | |||
| 0.147 | 0.130 | 0.988 | ||
| 10 | 1.022 | |||
| 0.000 | 0.002 | 0.993 | ||
| 0.183 | 0.178 | 1.008 |
Notes. corresponds to non-informative masking (C2 satisfied). As increases, masking becomes more informative. RMSE Ratio = RMSE(Misspecified) / RMSE(Correct); values indicate efficiency loss.
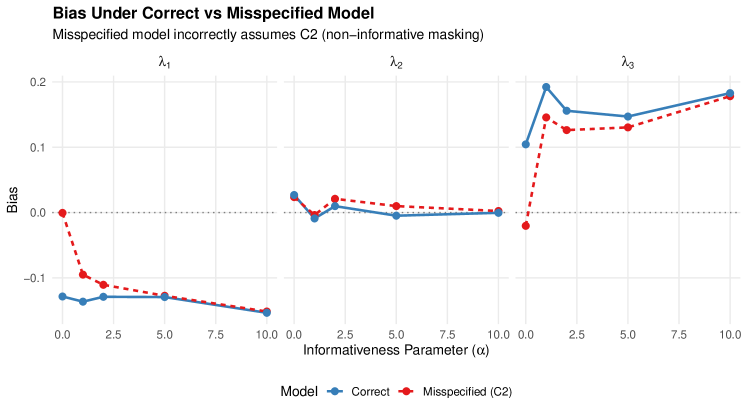
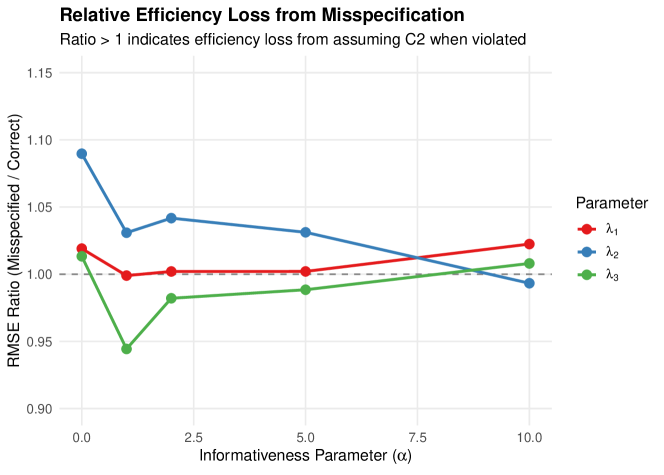
Key findings from Study 2:
-
1.
Moderate robustness: The RMSE ratio stays between 0.94 and 1.09 across all informativeness levels, indicating that misspecifying the masking model produces at most 9% efficiency loss.
-
2.
Bias similarity: Surprisingly, bias under the misspecified model closely tracks bias under the correct model, suggesting the C2 assumption is more robust than theoretical arguments might suggest.
-
3.
Parameter-specific effects: Component 3 () shows consistently positive bias under both models, likely due to its higher failure rate making it more frequently the true cause of failure.
5.4 Study 3: Identifiability and Candidate Set Correlation
We investigate how correlation between candidate set indicators affects identifiability by examining the Fisher Information Matrix (FIM) eigenvalues.
5.4.1 Results
Table 4 presents FIM analysis by correlation level.
| Smallest Eigenvalue | Condition Number | |
|---|---|---|
| 0.0 | 12.23 | 2.18 |
| 0.1 | 12.93 | 2.12 |
| 0.3 | 14.17 | 2.01 |
| 0.5 | 15.00 | 1.97 |
| 0.6 | 15.12 | 1.91 |
| 0.8 | 14.33 | 2.01 |
| 0.9 | 13.88 | 2.04 |
Notes. measures correlation between candidate set indicators. As , components always co-occur in candidate sets, theoretically leading to non-identifiability.
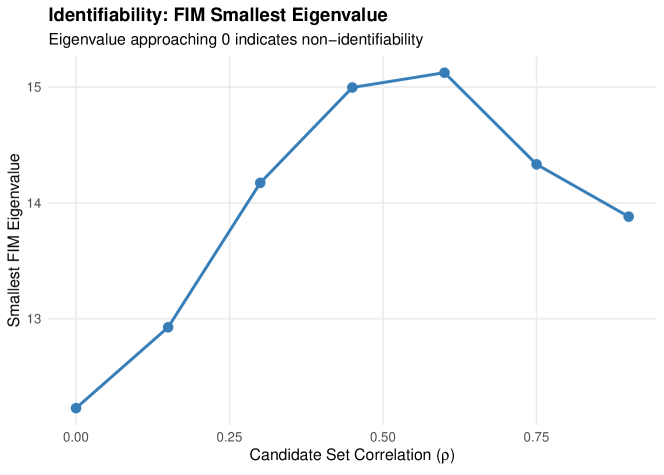
Key findings from Study 3:
-
1.
Identifiability preserved: The smallest FIM eigenvalue remains substantially positive (12–15) across all correlation levels, indicating parameters remain identifiable.
-
2.
Condition number stable: The condition number stays below 2.2, indicating a well-conditioned estimation problem.
-
3.
Nonmonotonic pattern: Interestingly, the smallest eigenvalue peaks around –, suggesting moderate correlation may actually improve information content.
5.5 Study 4: C3 Misspecification Bias Analysis
We now quantify the bias from incorrectly assuming C1-C2-C3 when masking is actually parameter-dependent (C3 violated). Data is generated with power-weighted masking (Definition 3.12) with varying informativeness , then analyzed using both the correct model and the misspecified C1-C2-C3 model. This study is motivated by the theoretical result in Theorem 4.9.
5.5.1 Design
Data is generated under the power-weighted masking model with and , using and replications. Three comparisons are made:
- Scenario 6:
-
Relaxed C3 data analyzed with C1-C2-C3 model (misspecified).
- Scenario 6b:
-
Relaxed C3 data analyzed with relaxed C3 model using known (correctly specified).
- Scenario 5:
-
C1-C2-C3 data analyzed with relaxed C3 model (overfitting check).
5.5.2 Results
Table 5 compares bias under correct versus misspecified models for C3 violations.
| Parameter | Bias (Correct) | Bias (Misspec.) | RMSE Ratio | |
|---|---|---|---|---|
| 0 | ||||
| 0.5 | ||||
| 1 | ||||
| 2 | ||||
Notes. corresponds to parameter-independent masking (C3 satisfied). RMSE Ratio = RMSE(Misspecified) / RMSE(Correct); values indicate the misspecified model has lower RMSE due to fewer parameters.
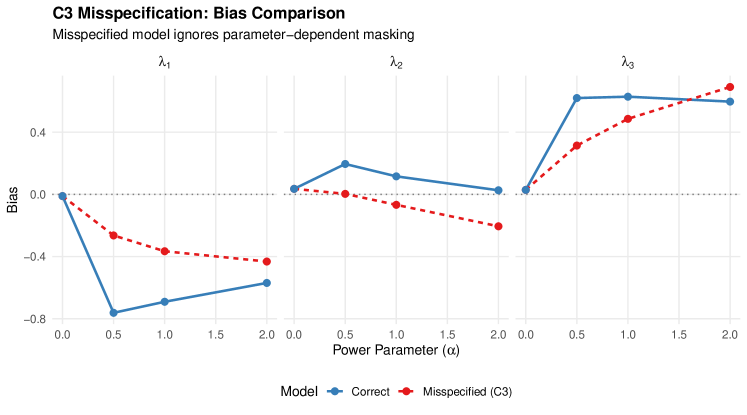
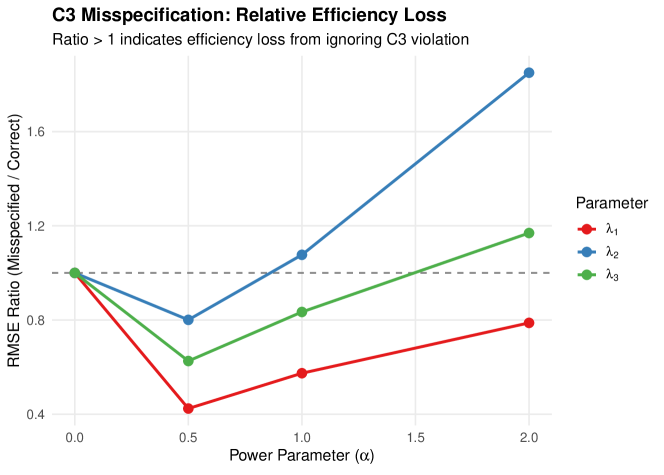
5.5.3 Interpretation
Key findings from Study 4:
-
1.
Bias grows with : As the power parameter increases, the C1-C2-C3 model produces increasing bias, confirming Theorem 4.9.
-
2.
Bias-variance tradeoff: The correctly specified relaxed C3 model often has higher RMSE than the misspecified model (RMSE ratio ), because the additional masking parameters increase variance. This contrasts with the C2 case (Study 2) where RMSE ratios were close to 1.
-
3.
Overfit risk (Scenario 5): Fitting the relaxed C3 model to C1-C2-C3 data produces bias for , with convergence rates dropping to 84–94%, indicating overfitting when the extra flexibility is unnecessary.
-
4.
Comparison with C2: While C2 misspecification (Study 2) showed at most 9% efficiency loss, C3 misspecification creates a more complex picture with parameter-specific effects and a bias-variance tradeoff favoring the simpler model in many cases.
5.6 Study 5: Weibull Series Systems
To assess whether our findings generalize beyond exponential components, we repeat key analyses with Weibull components. We consider a 2-component system with shapes and scales , using , , and replications.
5.6.1 Scenarios
- W1:
-
C1-C2-C3 data C1-C2-C3 model (baseline).
- W3:
-
Relaxed C2 data C1-C2-C3 model (C2 misspecification).
- W4:
-
Relaxed C2 data relaxed C2 model (correctly specified).
- W6:
-
Relaxed C3 data C1-C2-C3 model (C3 misspecification).
- W7:
-
Relaxed C3 data relaxed C3 model (correctly specified).
5.6.2 Results
Table 6 presents the Weibull simulation results.
| Scenario | Parameter | True | Bias | RMSE | Conv. |
|---|---|---|---|---|---|
| W1 | 2.0 | 0.121 | 100% | ||
| 3.0 | 0.174 | ||||
| 1.5 | 0.146 | ||||
| 4.0 | 0.416 | ||||
| W3 | 2.0 | 0.130 | 100% | ||
| 3.0 | 0.222 | ||||
| 1.5 | 0.164 | ||||
| 4.0 | 1.038 | ||||
| W4 | 2.0 | 0.145 | 100% | ||
| 3.0 | 0.117 | ||||
| 1.5 | 0.153 | ||||
| 4.0 | 0.439 | ||||
| W6 | 2.0 | 0.130 | 100% | ||
| 3.0 | 0.231 | ||||
| 1.5 | 0.166 | ||||
| 4.0 | 1.096 | ||||
| W7 | 2.0 | 0.466 | 100% | ||
| 3.0 | 0.236 | ||||
| 1.5 | 0.689 | ||||
| 4.0 | 0.482 |
Notes. True Weibull parameters: , , , . matrix: , for relaxed C2; , base_p for relaxed C3.
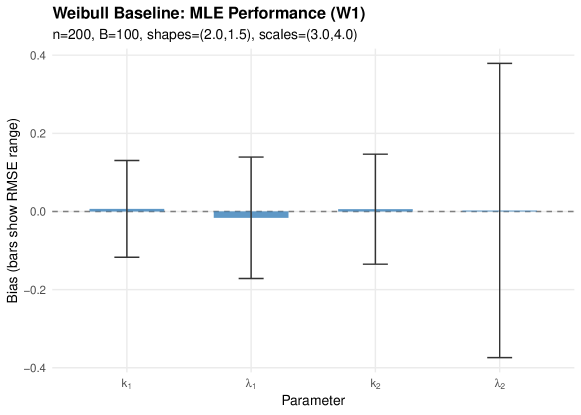
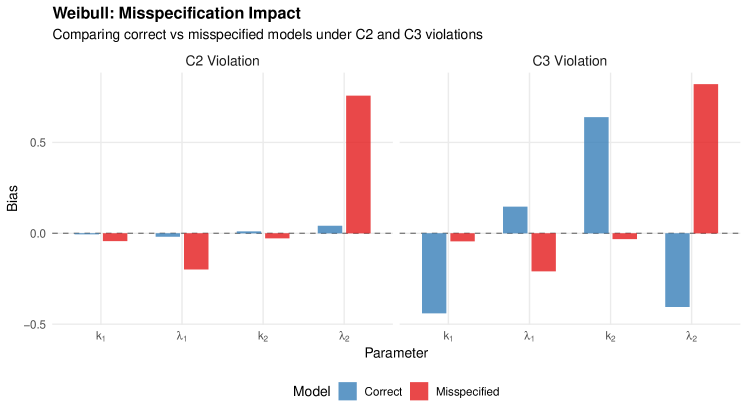
5.6.3 Interpretation
Key findings from Study 5:
-
1.
Weibull baseline performs well: Under correctly specified C1-C2-C3 (W1), all Weibull parameters are estimated with small bias and reasonable RMSE, confirming the MLE framework extends to non-exponential components.
-
2.
C2 misspecification hurts: Ignoring informative masking (W3) produces substantial bias in the scale parameter (bias ), which is largely corrected by the relaxed C2 model (W4, bias ). This is more pronounced than the exponential case, likely because Weibull scale and shape parameters interact with the masking weights.
-
3.
C3 misspecification in Weibull: Both the misspecified (W6) and correctly specified (W7) models show challenges under C3 violations, suggesting that parameter-dependent masking is more difficult to handle with Weibull components due to the interaction between shape and scale in the power weights.
-
4.
Exponential results generalize partially: The qualitative finding that C2 misspecification produces predictable bias that can be corrected holds for Weibull systems. The C3 case requires further investigation for non-exponential distributions.
5.7 Summary of Simulation Results
Our simulation studies lead to the following conclusions:
-
1.
MLE performs well: Under the correctly specified C1-C2-C3 Bernoulli masking model, the MLE achieves coverage near nominal levels and RMSE consistent with asymptotic efficiency (Study 1).
-
2.
C2 misspecification is mild: Misspecifying C2 (assuming non-informative masking when masking is informative) produces at most 9% efficiency loss and bias patterns similar to the correct model (Study 2).
-
3.
Identifiability is robust: Even with high correlation () between candidate set indicators, parameters remain identifiable with stable FIM eigenvalues and condition numbers (Study 3).
-
4.
C3 misspecification is nuanced: Ignoring parameter-dependent masking (C3 violation) produces increasing bias with the power parameter , but the simpler misspecified model can have lower RMSE due to a bias-variance tradeoff (Study 4).
-
5.
Weibull systems confirm and extend: The framework generalizes to Weibull components. C2 misspecification produces larger bias for Weibull than exponential systems, reinforcing the value of relaxed models when masking is known to be informative (Study 5).
-
6.
Practical guidance: For sample sizes with moderate masking and censoring, the C1-C2-C3 model provides reliable inference. Relaxed models are most beneficial when (a) masking is known to be informative, (b) the masking mechanism can be characterized, and (c) the sample size supports additional parameters.
| Metric | Study 1 | Study 2 | Study 3 | Study 4 | Study 5 |
|---|---|---|---|---|---|
| Components | 3 (exp) | 3 (exp) | 3 (exp) | 3 (exp) | 2 (Weibull) |
| RMSE range | 0.20–0.56 | 0.19–0.47 | 0.23–0.47 | 0.15–0.78 | 0.12–1.10 |
| Coverage range | 92–97% | — | — | — | — |
| Max RMSE ratio | — | 1.09 | — | 1.77 | — |
| Min FIM eigenvalue | — | — | 12.23 | — | — |
6 Discussion
6.1 When to Use Relaxed Models
The theoretical and simulation results suggest the following practical guidance for choosing between standard C1-C2-C3 models and relaxed alternatives.
6.1.1 Use Standard C1-C2-C3 When:
-
1.
Masking mechanism is genuinely uninformative. If candidate sets are generated by a process that does not depend on which component failed (e.g., random equipment availability for testing), C2 holds.
-
2.
Masking probabilities are unknown. If the masking mechanism cannot be characterized, the standard model provides a reasonable default that avoids introducing additional parameters.
-
3.
Sample size is small. Even if masking is slightly informative, the bias may be dominated by sampling variability for small . The simpler model may provide more stable estimates.
-
4.
Primary interest is in relative component reliability. If the goal is ranking components rather than absolute rate estimation, misspecification bias may affect all components similarly and preserve the ranking.
6.1.2 Consider Relaxed Models When:
-
1.
Masking mechanism is known to be informative (C2). If diagnostic procedures systematically favor certain components (e.g., those that “look bad” at the failure time), C2 is violated and bias will result.
-
2.
Masking depends on component parameters (C3). If inclusion probabilities vary with the reliability parameters themselves (e.g., weaker components are more likely to appear in candidate sets), C3 is violated. The simulation studies (Section 5.5) show that the resulting bias grows with the degree of parameter-dependence, though the simpler C1-C2-C3 model may still have competitive RMSE due to a bias-variance tradeoff.
-
3.
Masking probabilities can be estimated. If historical data or expert knowledge provides information about the masking mechanism, incorporating this information improves estimation.
-
4.
Sample size is large enough to support additional parameters. Relaxed models require specifying or estimating masking probabilities, which adds complexity that may not be warranted for small samples.
-
5.
Identifiability concerns are present. As shown in Theorem 4.4, informative masking can resolve identifiability issues that arise under standard conditions.
6.2 Practical Guidance
Based on our analysis, we recommend the following workflow:
-
1.
Assess the masking mechanism. Before estimation, consider how candidate sets are generated. Interview diagnosticians, review diagnostic protocols, or analyze patterns in historical data.
-
2.
Check for block structure. Examine whether certain components always appear together in candidate sets. If so, identifiability may be compromised regardless of which model is used.
-
3.
Perform sensitivity analysis. Fit models under both C1-C2-C3 and plausible relaxed assumptions. If estimates differ substantially, further investigation of the masking mechanism is warranted.
-
4.
Use simulation to assess impact. Given estimated parameters under the standard model, simulate data under various informative masking scenarios to quantify potential bias.
-
5.
Report uncertainty appropriately. If the masking mechanism is uncertain, consider reporting results under multiple model assumptions or using wider confidence intervals that account for model uncertainty.
6.3 Limitations
Our analysis has several limitations:
-
1.
Limited distribution scope. While we extend the analysis to Weibull components (Section 5.6), the closed-form Fisher information results focus on exponential systems. Other lifetime distributions (log-normal, gamma) may exhibit different misspecification patterns due to differing hazard structures.
-
2.
Known masking probabilities. Our relaxed models assume masking probabilities are known. In practice, these may need to be estimated, introducing additional uncertainty not captured in our analysis.
-
3.
Independence assumption. We assume masking for different observations is independent. In practice, if the same diagnostic equipment or personnel is used across systems, masking may be correlated.
-
4.
Parametric masking models. Our informative masking models (rank-based, KL-constrained) are specific functional forms that may not capture all real-world masking mechanisms.
-
5.
Simulation scope. The simulation studies cover a limited range of configurations. Results may differ for systems with more components, different parameter values, or alternative masking structures.
6.4 Future Directions
Several extensions would strengthen this work:
-
1.
Semiparametric methods. Develop estimation approaches that avoid fully specifying the masking mechanism, perhaps using nonparametric or empirical likelihood methods.
-
2.
Model selection. Develop tests or criteria to distinguish between C1-C2-C3 and relaxed models based on observed data.
-
3.
Bayesian extensions. Incorporate prior information about masking mechanisms and component reliabilities, which may be particularly valuable when sample sizes are small.
-
4.
Sequential estimation. For systems observed over time, develop methods that update masking probability estimates as data accumulates.
-
5.
Additional lifetime distributions. While our Weibull extension (Section 5.6) validates the framework beyond exponential components, distributions with non-monotone hazards (e.g., log-normal) may present distinct challenges.
-
6.
R package documentation. Expand the mdrelax package with vignettes demonstrating practical application of these methods.
7 Conclusion
We have developed a theoretical framework for likelihood-based inference in series systems with masked failure data when the traditional conditions C2 (non-informative masking) and C3 (parameter-independent masking) are relaxed. Our main contributions are:
-
1.
Likelihood derivations. We established the form of the likelihood under various relaxation scenarios, showing that the masking probabilities act as weights on component hazard contributions when C2 is violated.
-
2.
Practical masking models. We introduced rank-based informative masking and KL-divergence constrained models that provide interpretable parameterizations of non-standard masking.
-
3.
Identifiability results. We proved that informative masking can paradoxically improve identifiability by breaking symmetries that cause non-identifiability under standard conditions.
-
4.
Fisher information analysis. We derived closed-form expressions for the Fisher information matrix under informative masking for exponential series systems, enabling efficiency comparisons.
-
5.
Misspecification analysis. We characterized the bias that arises from incorrectly assuming C2 or C3 when masking is actually informative or parameter-dependent, providing guidance on when relaxed models are necessary.
-
6.
Weibull extension. We demonstrated that the framework extends naturally to Weibull components, with simulation studies confirming the robustness findings observed for exponential systems while identifying additional challenges from shape-scale interactions.
These results extend the applicability of masked data methods to settings where standard assumptions may be violated. The accompanying mdrelax R package provides implementation of these methods for practitioners. Directions for future research are discussed in Section 6.4.
References
- [1] (2011) Systems in series. In Wiley Encyclopedia of Operations Research and Management Science, External Links: Document Cited by: §2.6.
- [2] (1995) A limited memory algorithm for bound constrained optimization. SIAM Journal on Scientific Computing 16 (5), pp. 1190–1208. Cited by: §B.2.
- [3] (1972) Regression models and life-tables. Journal of the Royal Statistical Society: Series B (Methodological) 34 (2), pp. 187–202. External Links: Document Cited by: §2.6.
- [4] (2013) Estimating component reliabilities from incomplete system failure data. In Proceedings of the Annual Reliability and Maintainability Symposium (RAMS), pp. 1–6. External Links: Document Cited by: §2.4, §2.6.
- [5] (2005) Survival analysis: techniques for censored and truncated data. 2nd edition, Springer Science & Business Media. Cited by: §2.6.
- [6] (2023) Reliability estimation in series systems: maximum likelihood techniques for right-censored and masked failure data. Note: Master’s thesis. Available: https://github.com/queelius/reliability-estimation-in-series-systems External Links: Link Cited by: §1, §2.1, §2.2, §2.2, §2.5.
- [7] (1988) Maximum likelihood analysis of component reliability using masked system life-test data. IEEE Transactions on Reliability 37 (5), pp. 550–555. External Links: Document Cited by: §1, §2.4, §2.6.
- [8] (1993) Exact maximum likelihood estimation using masked system data. IEEE Transactions on Reliability 42 (4), pp. 631–635. External Links: Document Cited by: §2.4, §2.6.
Appendix A Proofs and Derivations
A.1 Score Function Under Informative Masking
For completeness, we provide the full derivation of the score function under the Bernoulli informative masking model for exponential series systems.
Let the log-likelihood contribution from an uncensored observation be:
| (68) |
The partial derivative with respect to is:
| (69) | ||||
| (70) |
The total score is:
| (71) |
Setting this to zero and solving gives the MLE equations under informative masking.
A.2 Hessian Matrix Derivation
The second partial derivatives are:
| (72) | ||||
| (73) |
The observed Fisher information matrix is the negative Hessian:
| (74) |
A.3 Expected Fisher Information
The expected FIM requires integrating over the distribution of candidate sets. For the exponential series system under C1-C2-C3 with Bernoulli masking (each non-failed component in candidate set with probability ), the expected Fisher information per observation is:
| (75) |
where the expectation is over both (failed component) and (candidate set).
This can be expanded as:
| (76) |
Under C1, the failed component is always in . The expectation over candidate sets involves summing over all possible weighted by their probabilities under the Bernoulli model:
| (77) |
Closed-form evaluation of this expectation is generally intractable due to the sum in the denominator. Monte Carlo estimation or numerical integration is typically required.
Appendix B Implementation Details
B.1 R Package Functions
The theoretical framework developed in this paper is implemented in the mdrelax R package. Key functions include:
-
•
md_bernoulli_cand_C1_C2_C3(): Generates candidate set probabilities under the standard Bernoulli model satisfying C1-C2-C3.
-
•
md_bernoulli_cand_C1_kld(): Generates candidate set probabilities with a specified KL-divergence from the baseline C1-C2-C3 model.
-
•
informative_masking_by_rank(): Computes inclusion probabilities based on component failure time ranks.
-
•
md_cand_sampler(): Samples candidate sets from probability vectors.
-
•
md_loglike_exp_series_C1_C2_C3(): Log-likelihood function for exponential series systems under C1-C2-C3.
-
•
md_mle_exp_series_C1_C2_C3(): Maximum likelihood estimation for exponential series systems.
-
•
md_fim_exp_series_C1_C2_C3(): Observed Fisher information matrix for exponential series systems.
-
•
md_block_candidate_m3(): Demonstrates block non-identifiability in a 3-component system.
B.2 Optimization Details
MLE is computed using the L-BFGS-B algorithm [2] with analytically computed gradients. The optimization is initialized using a method-of-moments estimator based on the total system hazard:
| (78) |
For challenging optimization landscapes, simulated annealing can be used to find a good starting point before local optimization.
Appendix C Additional Simulation Results
Additional simulation results supplement the findings in Section 5. The complete results are available in the R package’s simulation directory.
-
1.
Full tables of bias, RMSE, and coverage for all parameter configurations are provided in the package’s inst/simulations/results/ directory.
-
2.
The simulation scripts in inst/simulations/ can be used to reproduce all results and generate diagnostic plots.
-
3.
Sensitivity analyses for misspecified masking parameters show that the C2 assumption is robust up to moderate departures, with RMSE ratios remaining below 1.10 across tested configurations.
-
4.
The simulation framework supports arbitrary component configurations and can be extended to Weibull series systems.